
Two years ago I started a series about using the analytics publicly released by the USA government to gleam some information about H&R Block's mobile apps. I'm a few months late this year, but it's time to update the numbers for the 2020 tax year. The 2019 numbers are available here.
This time I went ahead and updated the code to make parsing a little more flexible:
:::python
#!/usr/bin/env python
from __future__ import print_function
import sys
import json
import re
def parse_subtokens(tokens):
""" Parses subtokens and returns a dictionary. If invalid, None is returned.
We expect all user agents to start with "HBR MOBILE", after which we can encounter
OS, device, app, authentication, browser, and app version strings. Everything except
version is matched using exact string comparisons. Version uses a regex.
"""
res = {'OS': 'N/A', 'DEVICE': 'N/A', 'APP': 'N/A', 'AUTH': 'N/A', 'VERSION': 'N/A', 'BROWSER': 'N/A'}
token_mapping = {'ANDROID': 'OS', 'IOS': 'OS',
'PHONE': 'DEVICE', 'TABLET': 'DEVICE',
'MYBLOCK': 'APP', 'TAXES': 'APP',
'TOUCHID': 'AUTH', 'FACEID': 'AUTH',
'Mozilla': 'BROWSER'}
if tokens[0] != 'HRB':
return None
if tokens[1] != 'MOBILE':
return None
for token in tokens[2:]:
if token in token_mapping:
res[token_mapping[token]] = token
elif re.match('v?[0-9]+\.[0-9]+\.[0-9]+', token):
res['VERSION'] = token
else:
print('WARNING: Unknown token: %s from %s' % (token, str(tokens)), file=sys.stderr)
# Cleanups:
# 1) Some versions of the Android app prefix 'v' onto version
if res['VERSION'][0] == 'v':
res['VERSION'] = res['VERSION'][1:]
assert len(res) == 6
return res
def is_hrb(year, filter, line):
""" Validate that a line should be parsed and added to the buckets.
Specifically, entry should contain the right year, be a HRB user-agent,
and contain the filter keyword if one was provided.
"""
if line[:4] != year:
return False
if line[11:14] != 'HRB':
return False
if not filter is None and not filter in line:
return False
return True
if __name__ == '__main__':
if len(sys.argv) < 3:
print('Usage: %s <tax-year> [filter] <filepath>' % sys.argv[0])
sys.exit(0)
if len(sys.argv) == 3:
filter = None
else:
filter = sys.argv[2]
with open(sys.argv[-1], 'r') as ifile:
data = [line.strip() for line in ifile if is_hrb(sys.argv[1], filter, line)]
buckets = {
'OS': {
'IOS': 0,
'ANDROID': 0,
},
'DEVICE': {
'PHONE': 0,
'TABLET': 0,
},
'APP': {
'MYBLOCK': 0,
'TAXES': 0,
},
'AUTH': {
'TOUCHID': 0,
'FACEID': 0,
'N/A': 0,
},
'VERSION': {},
'BROWSER': {},
}
for line in data:
tokens = line.split(',')
if len(tokens) != 3:
print('WARNING: Cannot tokenize: %s' % line, file=sys.stderr)
continue
subtokens = parse_subtokens(tokens[1].split('-'))
if subtokens is None:
print('WARNING: Cannot subtokenize: %s' % tokens[1].split('-'), file=sys.stderr)
continue
try:
count = int(tokens[-1])
except ValueError:
print('WARNING: Could not parse count from: %s' % line, file=sys.stderr)
continue
buckets['OS'][subtokens['OS']] += count
buckets['DEVICE'][subtokens['DEVICE']] += count
buckets['APP'][subtokens['APP']] += count
buckets['AUTH'][subtokens['AUTH']] += count
if subtokens['VERSION'] in buckets['VERSION']:
buckets['VERSION'][subtokens['VERSION']] += count
else:
buckets['VERSION'][subtokens['VERSION']] = count
if subtokens['BROWSER'] in buckets['BROWSER']:
buckets['BROWSER'][subtokens['BROWSER']] += count
else:
buckets['BROWSER'][subtokens['BROWSER']] = count
print(json.dumps(buckets, indent=4))
I've been collecting this data since 2016 and I'm happy to share upon request.
Results
Here are the results for 2020, in no particular order:
- From January 13 through April 14, 0 requests were made by MyBlock and 563,138 by Taxes.
- 545,368 requests were made from phones while 17,770 were tablets; about 97% of the requests were phones.
- 100% of requests were made by devices running iOS.
- Seven versions of Taxes appear in the dataset: 9.2.0, 9.2.1, 9.3.0, 9.3.1, 9.4.0, 9.5.0, and 9.6.0.
- 0.2% of requests contain "Mozilla" in the user-agent.
And the security question from the original blog post:
- 221,827 requests used TouchID, 265,313 FaceID, and 75,998 showed neither keyword; 39%, 47%, and 14%, respectively.
Comparison to 2019
- In 2019, the majority of requests were made by Taxes. Now in 2020, only Taxes appears in the data.
- The change in usage of TouchID, FaceID, and neither is -20%, 21%, and -1%, respectively.
Discussion
I'm no longer seeing requests from Android devices or the MyBlock app, implying either something has been discontinued, or is no longer using the original custom user agents.
We've also reached the point where FaceID has finally overtaken TouchID. Here's a graphic capturing the change:
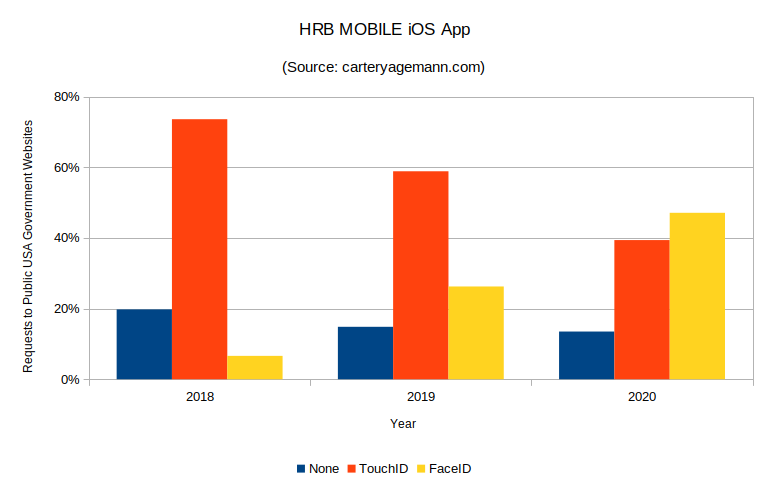
We'll see next year how the trends change. Thanks for reading!